Table of Content
This is a comprehensive blind listening study comparing top text to speech models for real-world applications
TL;DR
Contents
The Voice Selection Problem
Provider Selection
Scenario Design
Evaluation Protocol
Results Summary
Results Deep Dive:
Live Conversation/Agent
Customer Support
Education
Medical/Healthcare
About the Author
Acknowledgements
References
Market Research & Industry Analysis:
Voice Quality & Naturalness Assessment:
TTS Technology & Trends:
Applied Research:
Best AI Voices for Customer Support, Medical, Education, and Live Conversation Agents
We Tested 100+ AI Voices Across 5 Major Providers — Here Are the Best for Customer Support, Medical, Education, and Live Conversation Agents


This is a comprehensive blind listening study comparing top text to speech models for real-world applications
The Text to Speech (TTS) market is experiencing explosive growth, projected to reach between $9.3 billion and $12.4 billion by 2030, driven by advances in deep learning and increasing demand for accessible digital content.
But, there is a problem, with tens of models and hundreds of voices and personalities, choosing the correct voice is very difficult. The choice can make a real difference as lack of emotion can instantly make the end users feel that the product is a poor implementation.
This is the problem facing every product manager, developer, and designer working with conversational AI. Vendor marketing materials provide little differentiation—everyone promises the same thing. Provider documentation uses inconsistent terminology: what one calls "warm" another describes as "friendly," and a third labels "empathetic." And conducting real-world testing across all these options is prohibitively time-consuming.
So we did the heavy lifting for you. In this study we compared voices and models from top TTS providers like Gemini, OpenAI, ElevenLabs, Polly, and Deepgram. We compiled our results and finding in this article which article gives you:
- Data-Backed Recommendations: Instantly find the best voices for customer support, medical, and education.
- Testing Tool: Use our open-source VoiceArena platform to test the top voices with your own scripts/text to generate voice for your specific application.
TL;DR
What we did:
- Blind listening comparison of 100+ voices across Gemini, ElevenLabs, OpenAI, Polly, and Deepgram
- Evaluated performance in Customer Support, Medical, Education, and Live Conversation scenarios
- Built VoiceArena, an open-source platform for side-by-side voice testing
Top recommendations:
- Live Conversation: Ruth (Polly), Echo (OpenAI)
- Customer Support: Harmonia (Deepgram), Vesta (Deepgram)
- Education: Stephen (Polly), Sadaltager (Gemini)
- Medical: Harmonia (Deepgram), Shimmer (OpenAI)
Key insights:
- Generative voice models (Polly's advanced lineup) significantly outperform standard neural voices
- Deepgram dominates customer support applications through strategic specialization
- Provider selection should consider technological trajectory, not just current quality
- Cost differences between providers are negligible compared to voice quality impact
Test yourself: https://voicelmarena.vercel.app/
Contents
Problem: The Voice Selection Problem
Approach: How We Conducted the Blind Listening Study
Findings: Top Voice Recommendations by Use Case
References: References & Acknowledgements
The Voice Selection Problem
You need to choose a text-to-speech voice for your customer support system. You open the documentation for Amazon Polly and find 60+ voices. Google Cloud offers 40+ more. OpenAI has a dozen. ElevenLabs boasts hundreds. Each provider claims their voices are "natural," "expressive," and "human-like."
Over the course of this research, We:
- Conducted blind listening tests across 100+ voices from five major providers
- Generated and evaluated audio samples for four critical real-world scenarios
- Built an open-source platform enabling anyone to replicate these tests
- Identified clear winners for customer support, medical, education, and live conversation applications
What follows isn't marketing copy or vendor-provided specifications—it's the result of systematic listening, comparison, and analysis. More details about the experiment is below.
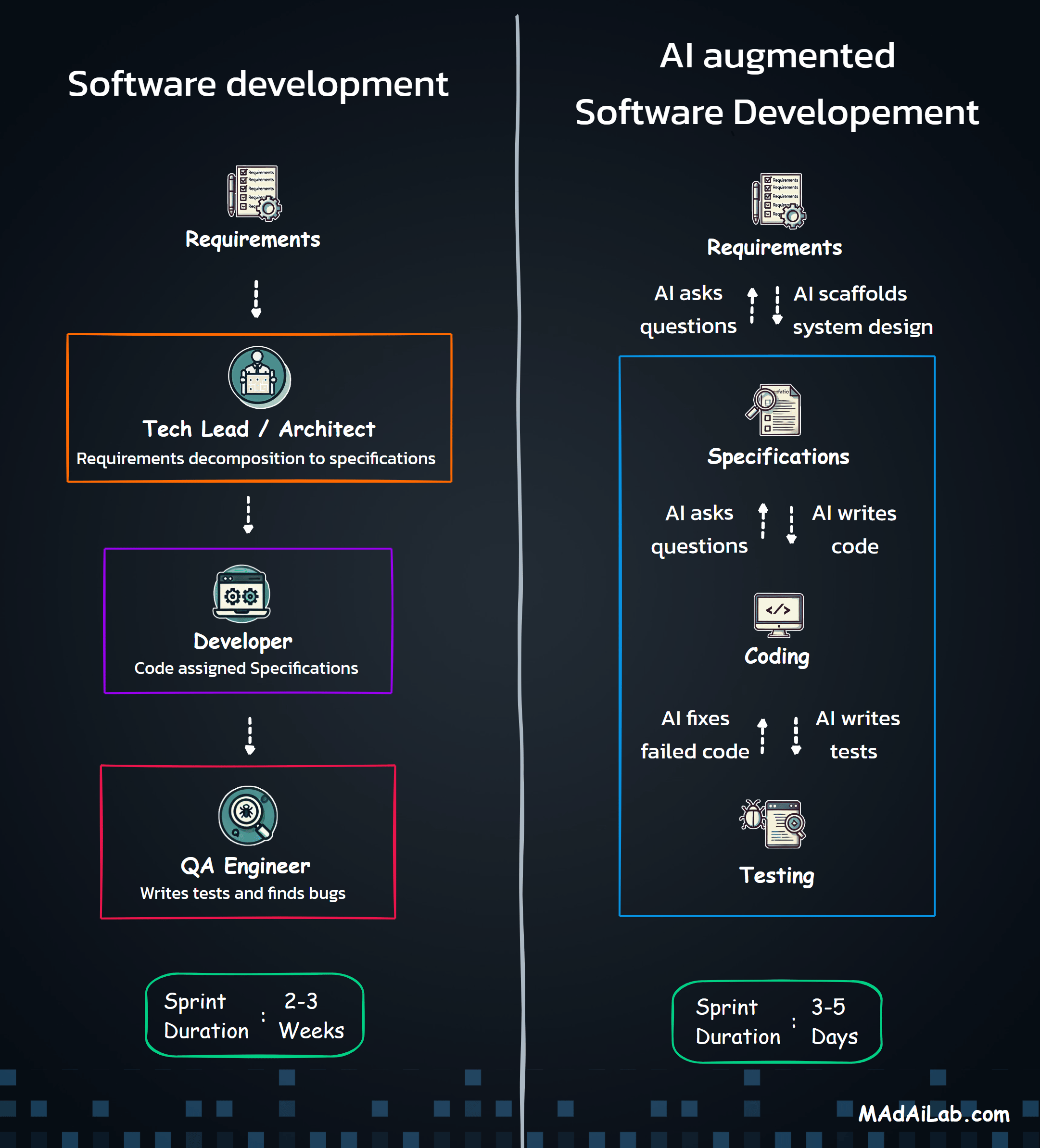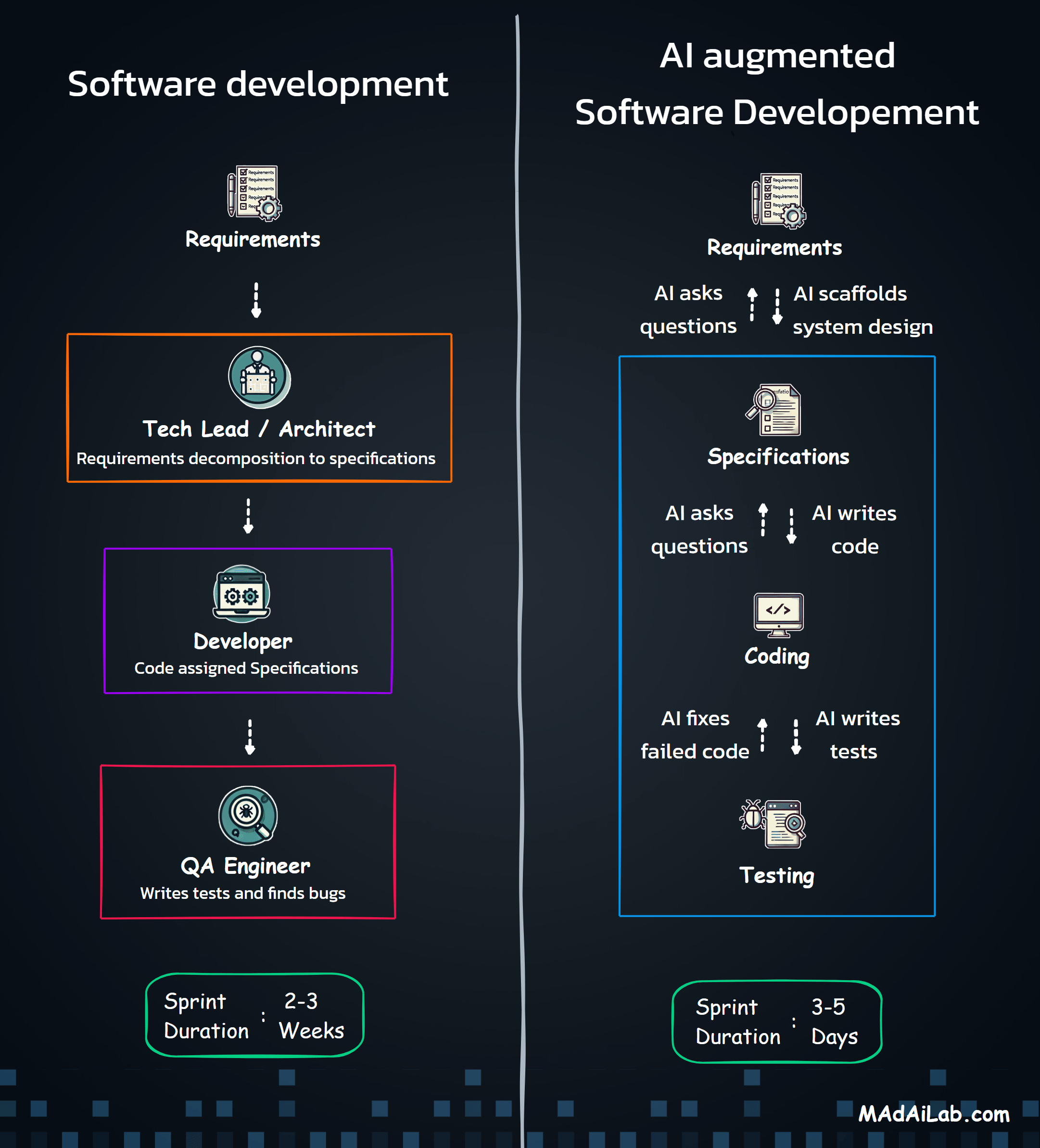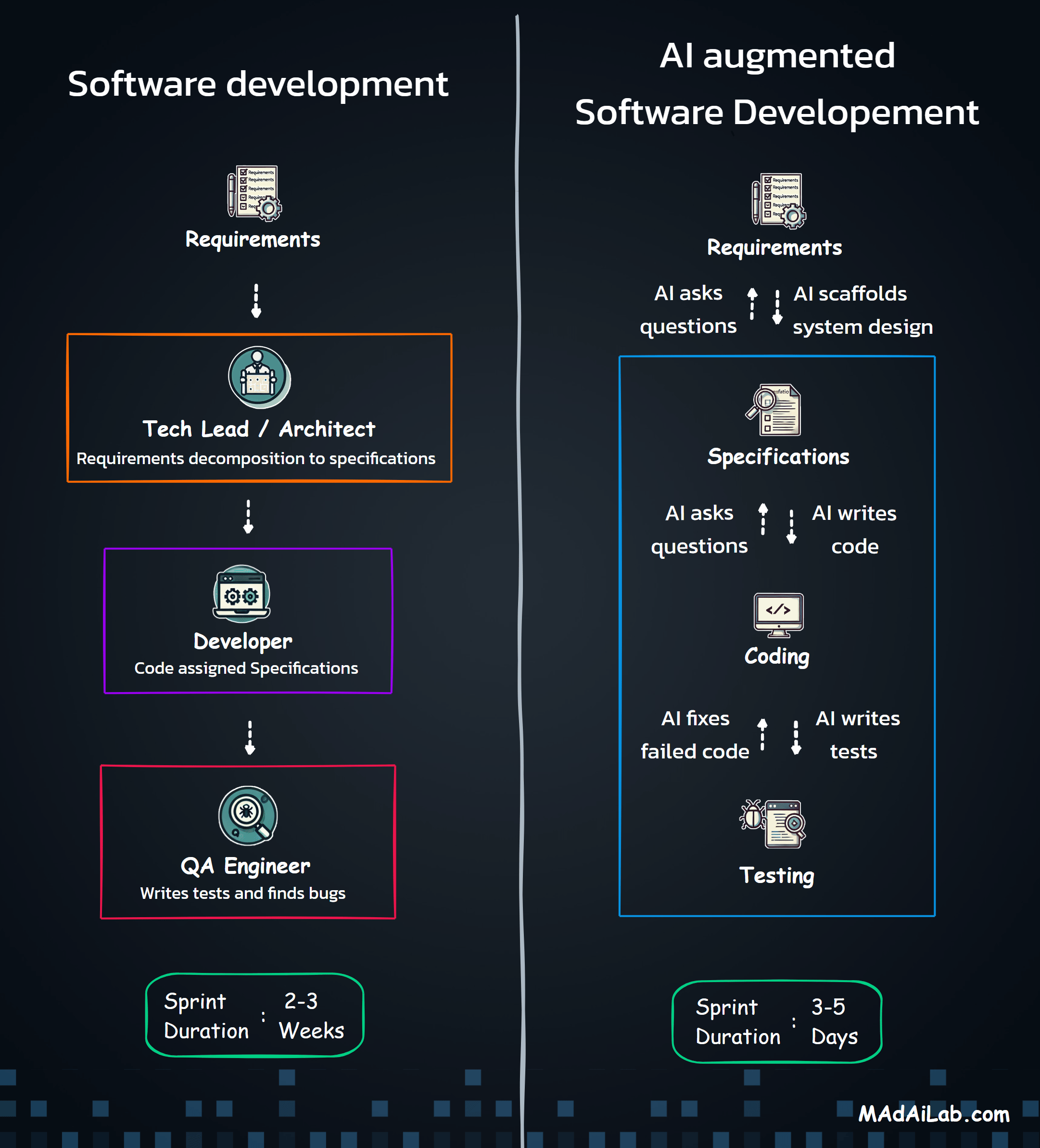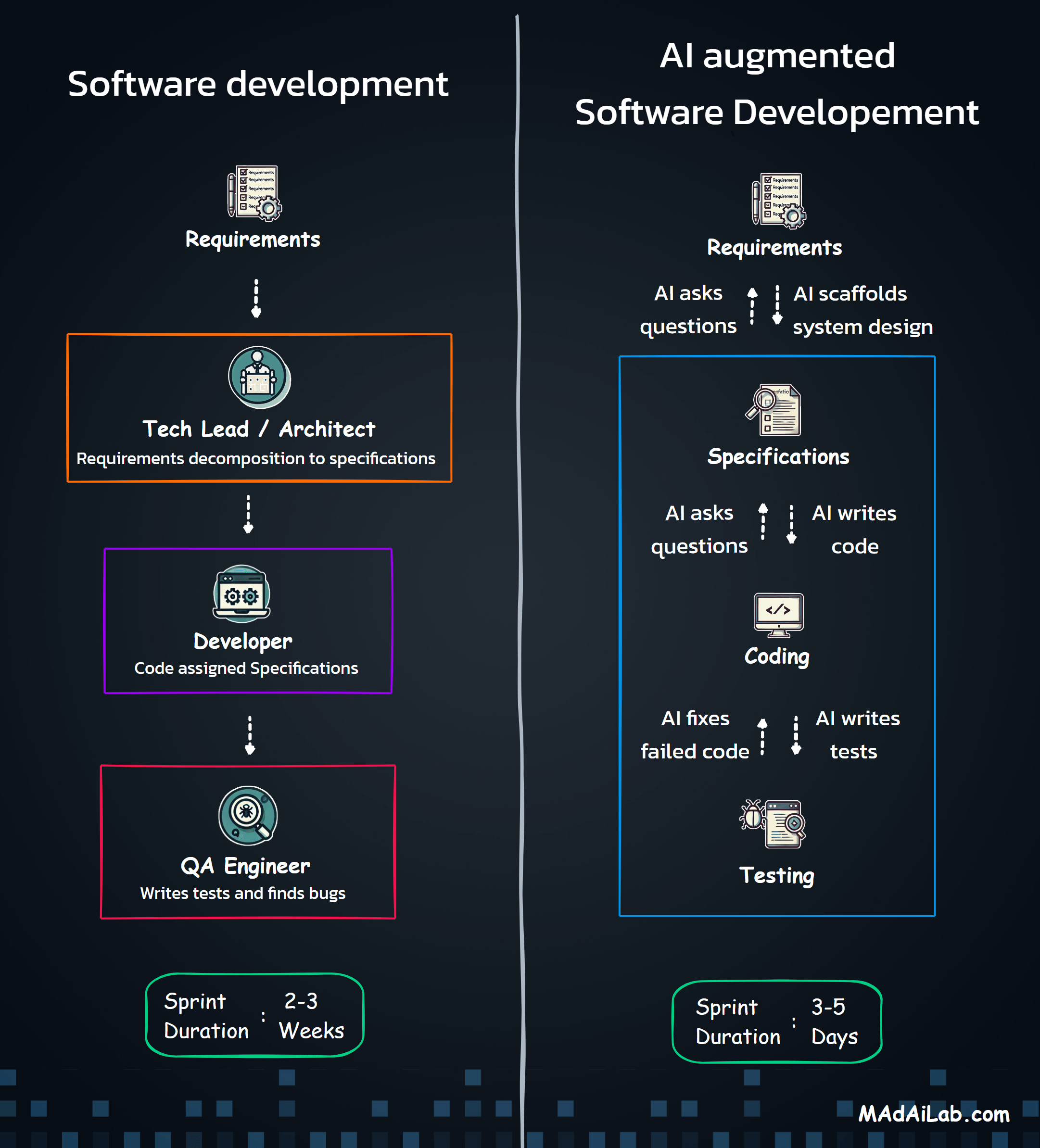
Research Methodology: How We Conducted the Blind Listening Study
Subjective evaluation of voice quality is inevitable—what sounds "natural" is ultimately a human judgment. But the methodology behind that evaluation can still be systematic, rigorous, and transparent.
Provider Selection
Who we tested:
- Google Gemini (text-to-speech API)
- ElevenLabs (specialized AI voice platform)
- OpenAI (GPT-4 with audio capabilities)
- Amazon Polly (AWS text-to-speech service)
- Deepgram (conversational AI voice platform)
Why these providers:
These represent the market leaders with robust API access, extensive voice catalogs, and demonstrated enterprise adoption. They span the spectrum from general-purpose cloud providers (AWS, Google) to specialized AI voice companies (ElevenLabs, Deepgram) to frontier AI labs (OpenAI).
Voice catalog scope:
All default voices from each provider were evaluated—approximately 100 voices total. This study excluded custom voice cloning, premium add-ons, or enterprise-only options to keep the comparison accessible and reproducible
Scenario Design
Rather than testing voices in isolation, We evaluated them within four critical real-world contexts:
| Context | Use Case | Sample Text | Evaluation Focus |
| Customer Support | Apologetic responses, technical troubleshooting and empathetic problem-solving. | "I sincerely apologize for the inconvenience... Let me walk you through the troubleshooting steps..." | Does the voice convey genuine empathy and warmth while inspiring trust? |
| Medical/Healthcare | Prescription instructions, medication timing, and disease explanations. | "Take this medication twice daily... Do not exceed the recommended dosage." | Does the voice balance authority with approachability and deliver sensitive information clearly? |
| Education | Book dictation, answering student questions, and delivering instructional content. | "The mitochondria is often called the powerhouse of the cell..." | Does the voice maintain engagement during long content and emphasize key concepts naturally? |
| Live Conversation/Agent | Real-time dialogue, sentiment-adaptive responses, and short interactions. | "Yes, absolutely!", "I'm not sure about that.", "Let me check on that for you." | Can the voice shift emotional registers quickly and sound natural in brief exchanges? |
Evaluation Protocol
To minimize bias and ensure objective comparison, We employed a blind testing methodology:
- Audio generation: Using VoiceArena, We generated audio samples for all 100 voices across each scenario's test scripts
- Randomization: Samples were shuffled so provider and voice name weren't visible during evaluation
- Listening sessions: Each voice was evaluated independently without knowing which provider it came from
- Primary criterion: Naturalness — Does this sound like a real human speaking? Are there artifacts, unnatural pauses, or robotic inflections?
- Secondary criterion: Emotional appropriateness — Does the tone match the context? Would this voice inspire the right response (trust, engagement, calm) in a real user?
- Round-robin selection: After initial listening, conducted multiple comparison rounds, systematically narrowing the field to identify the top two performers per scenario
Key Findings: Top Voice Recommendations by Use Case
After systematically evaluating 100+ voices across four key business scenarios, clear winners emerged. The table below provides our top recommendations at a glance.
Results Summary
Use this table to find the winning voice for your specific scenario
| Use Case | Recommendation #1 | Key Attributes | Recommendation #2 | Key Attributes |
| Live Conversation/Agent | Ruth (Polly) | Highly expressive, adaptive, emotionally engaged, colloquial | Echo (OpenAI) | Warm, natural, friendly, resonant, conversational |
| Customer Support | Harmonia (Deepgram) | Empathetic, clear, calm, confident | Vesta (Deepgram) | Natural, expressive, patient, empathetic |
| Education | Stephen (Polly) | Assertive, knowledgeable, emotionally adept, near-human | Sadaltager (Gemini) | Knowledgeable, intelligent, articulate, well-informed |
| Medical | Harmonia (Deepgram) | Empathetic, clear, calm, confident | Shimmer (OpenAI) | Soothing, neutral warmth, clear, non-intrusive |
Results Deep Dive:
Live Conversation/Agent
Context: Requires spontaneous, emotionally flexible voices for real-time dialogue.
- Winner: Ruth (Amazon Polly)
- Why it won: Unmatched emotional range and natural prosody. Handled colloquial phrases ("Got it!") convincingly, feeling responsive rather than scripted. (Note: This is a generative voice, representing Polly's next-gen tech).
- Best for: Real-time customer interactions, voice assistants, and phone-based agents.
- Runner-up: Echo (OpenAI)
- Why it won: Exceptional warmth and consistent friendliness. Less dynamic than Ruth, but its soothing, clear quality reduces listener fatigue.
- Best for: Applications where a steady, reassuring presence is key (e.g., wellness apps, onboarding).
Customer Support
Context: Must convey empathy, clarity, and authority to de-escalate tension.
- Winner: Harmonia (Deepgram)
- Why it won: A perfect balance of professionalism and warmth. The apology script sounded genuine, and its thoughtful, measured pacing builds trust.
- Best for: IVR systems, customer service bots, and escalation management.
- Runner-up: Vesta (Deepgram)
- Why it won: Highlights Deepgram's strategic focus on B2B conversational AI (both winners are theirs). Vesta is slightly warmer than Harmonia, making it ideal for friendlier, consumer-facing brands.
- Best for: Consumer-facing (B2C) support.
Education
Context: Must sustain engagement during long-form content and avoid monotony.
- 🥇 Winner: Stephen (Amazon Polly)
- Why it won: Sounds like a knowledgeable instructor, not a robot. Naturally emphasizes key terms and avoids "TTS fatigue" in long audio samples. (Note: Also a Polly generative voice).
- Best for: E-learning platforms, audiobook narration, and instructional videos.
- Runner-up: Sadaltager (Google Gemini)
- Why it won: Brings intellectual authority and gravitas. It sounds like a subject matter expert, making it highly credible.
- Best for: Higher education, academic, or technical content where formality is a plus.
Medical/Healthcare
Context: High-stakes; requires authority, clarity, and empathy to build trust.
- Winner: Harmonia (Deepgram)
- Why it won: Its customer support strengths (calm, clear, confident) translate perfectly. It delivers instructions with authority while remaining supportive and building patient confidence.
- Best for: Medication reminders, patient education, and telehealth interfaces.
- Runner-up: Shimmer (OpenAI)
- Why it's competitive: Offers "neutral warmth"—caring without being overly emotional. Its soothing, non-intrusive tone is excellent for delicate topics.
- Best for: Mental health applications, wellness check-ins, and delivering sensitive diagnostic news.
About the Author
I am a Data Scientist with 5+ years of experience specializing in the end-to-end machine learning lifecycle, from feature engineering to scalable deployment. I build production-ready deep learning and Generative AI applications , with expertise in Python, MLOps, and Databricks. I hold an M.S. in Business Analytics & Information Management from Purdue University and a B.Tech from a B.Tech in Mechanical Engineering from the Indian Institute of Technology, Indore. You can connect with me on LinkedIn at linkedin.com/in/mayankbambal/ and I write weekly on medium: https://medium.com/@mayankbambal
Dr. Rohit Aggarwal is a professor, AI researcher and practitioner. His research focuses on two complementary themes: how AI can augment human decision-making by improving learning, skill development, and productivity, and how humans can augment AI by embedding tacit knowledge and contextual insight to make systems more transparent, explainable, and aligned with human preferences. He has done AI consulting for many startups, SMEs and public listed companies. He has helped many companies integrate AI-based workflow automations across functional units, and developed conversational AI interfaces that enable users to interact with systems through natural dialogue.
References & Acknowledgements
Acknowledgements
Prof. Rohit Aggarwal — For envisioning VoiceArena as an accessible, open-source testing platform that democratizes voice evaluation for non-technical users. His strategic vision shaped both the platform architecture and research methodology.
MAdAiLab — For sponsoring API costs for the experimentation, without which we wouldn’t be able to do extensive testing.
References
Market Research & Industry Analysis:
- Verified Market Research. (2024). Text To Speech (TTS) Market Size, Share, Trends & Forecast. Projected market growth: $2.96B (2024) to $9.36B (2032) at 15.5% CAGR.
- Globe Newswire. (2024). Text-to-Speech Strategic Industry Report 2024. Market analysis projecting $9.3B by 2030, driven by AI-powered voice solutions.
- Straits Research. (2025). Text to Speech Software Market Size & Outlook, 2025-2033. Projected growth to $12.4B by 2033 at 16.3% CAGR.
Voice Quality & Naturalness Assessment:
- Mittag, G., et al. (2021). Deep Learning Based Assessment of Synthetic Speech Naturalness. ArXiv:2104.11673. Established CNN-LSTM framework for TTS naturalness evaluation.
- WellSaid Labs. Defining Naturalness as Primary Driver for Synthetic Voice Quality. Industry framework for Likert-scale naturalness assessment (5-point scale).
- Softcery. (2025). AI Voice Agents: Quality Assurance - Metrics, Testing & Tools. Mean Opinion Score (MOS) benchmarks; scores above 4.0 considered near-human quality.
TTS Technology & Trends:
- ArXiv. (2024). Towards Controllable Speech Synthesis in the Era of Large Language Models: A Survey. Analysis of emotion, prosody, and duration control in modern TTS systems.
- AI Multiple. (2023). Top 10 Text to Speech Software Comparison. Overview of deep learning advancements enabling human-like speech synthesis.
- TechCrunch. (2024). Largest text-to-speech AI model yet shows 'emergent abilities'. Discussion of scaling effects in generative voice models.
Applied Research:
- Scientific Reports. (2025). Artificial intelligence empowered voice generation for amyotrophic lateral sclerosis patients. Medical applications of AI-generated voice.
- ScienceDirect. (2025). The Use of a Text-to-Speech Application as a Communication Aid During Medically Indicated Voice Rest. Clinical TTS evaluation study.
Tags: #Text-to-Speech, #Speech-to-Text, #GenerativeAI, #ConversationalAI, #VoiceArena, #AIAgents, #MADAILABS