Table of Content
What You’ll Learn in Five Minutes
Background Context
Step 1: Identify Common Reconciliation Errors with GPT
Step 2: Generate Synthetic Data That Bites
Step 3: Write Requirements Before Touching the Tool
Step 4: Use AI to Scaffold n8n from the Requirements
Step 5: Build and Harden the n8n Workflow
Step 6: What You Can Reuse Tomorrow
Notes on Scope
Acknowledgments
About the Author
FinOps: n8n AI workflow for financial reconciliation
Using AI to scaffold auditable n8n workflows for financial reconciliation — from written requirements to reliable automation.


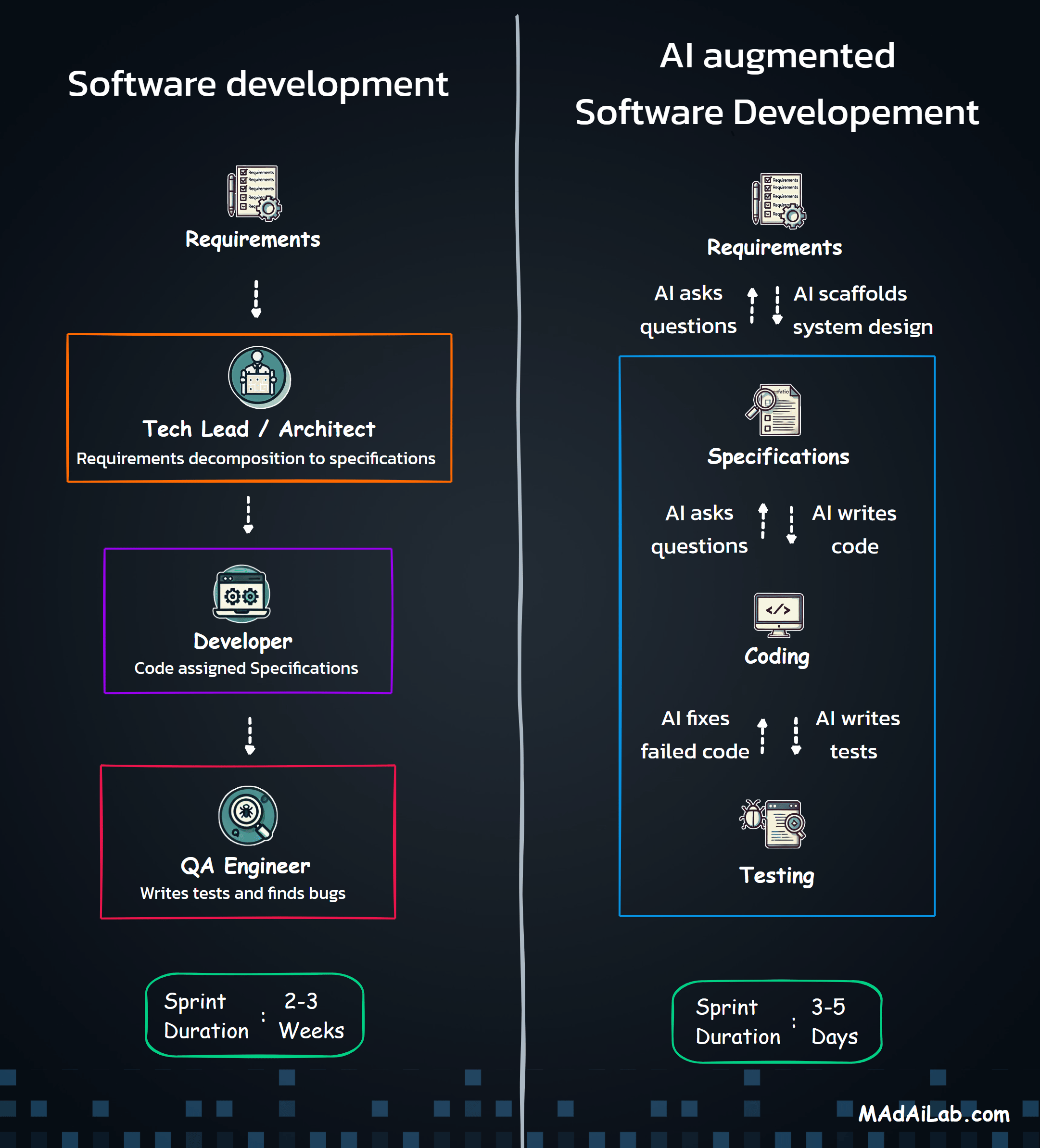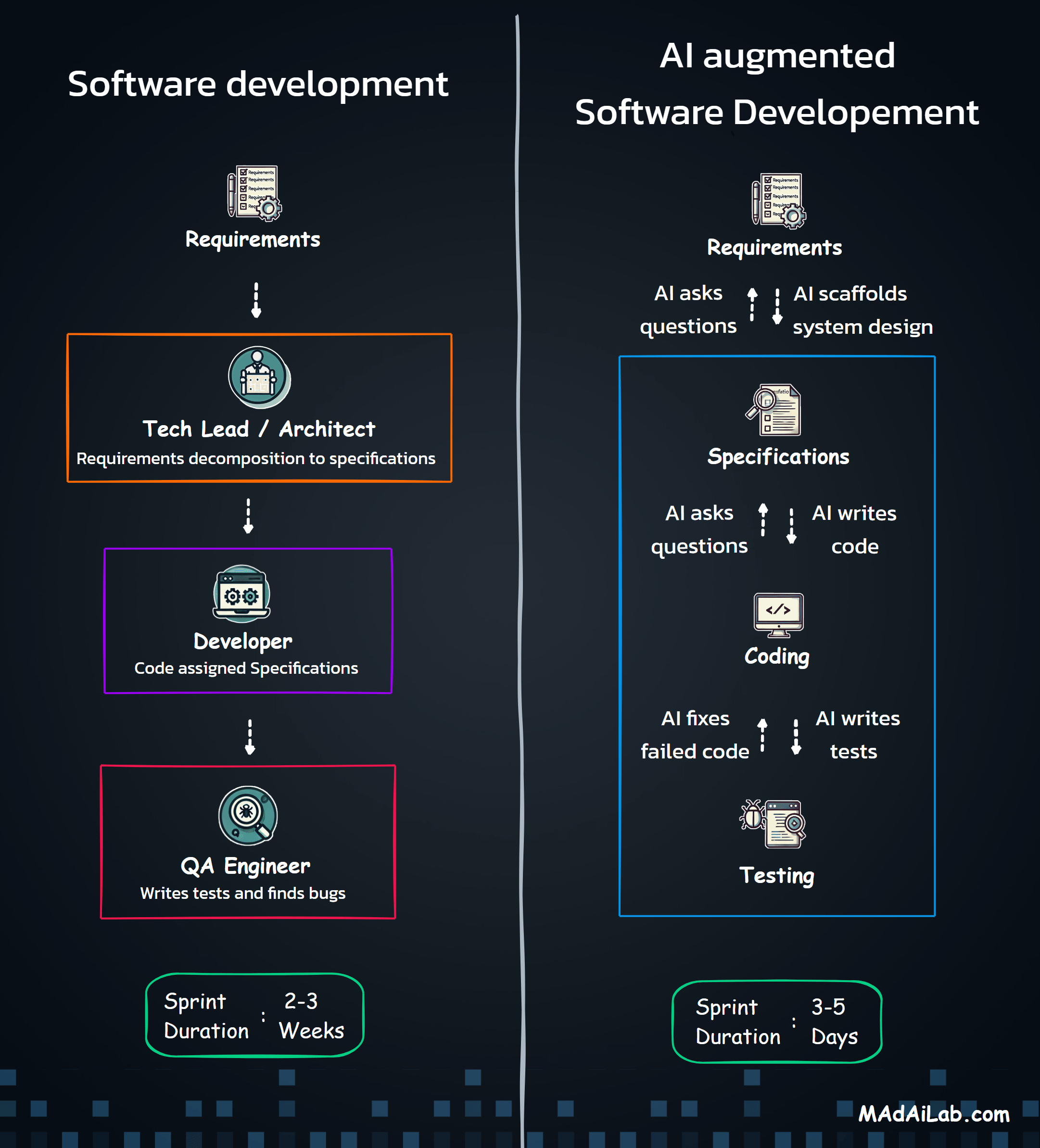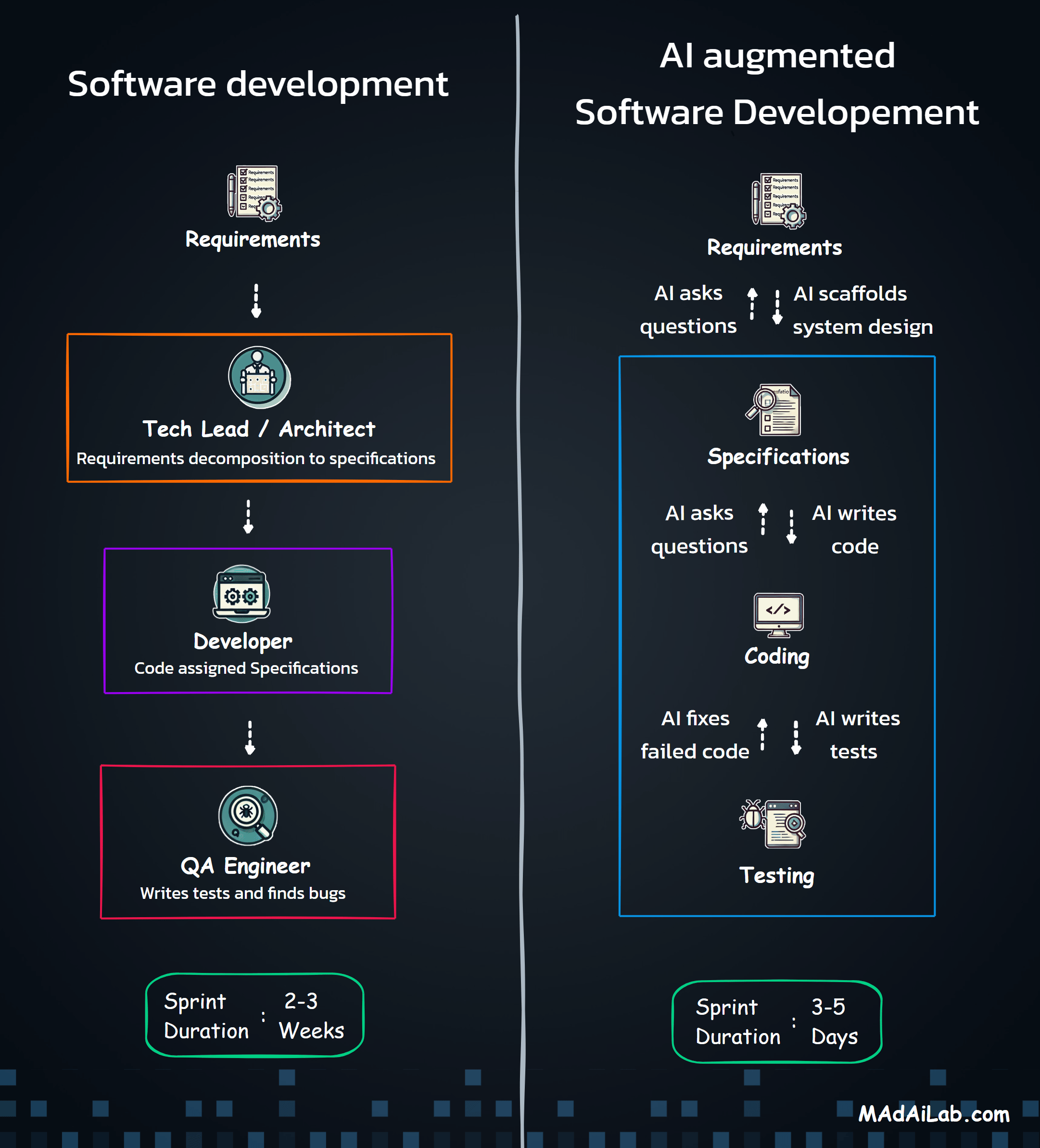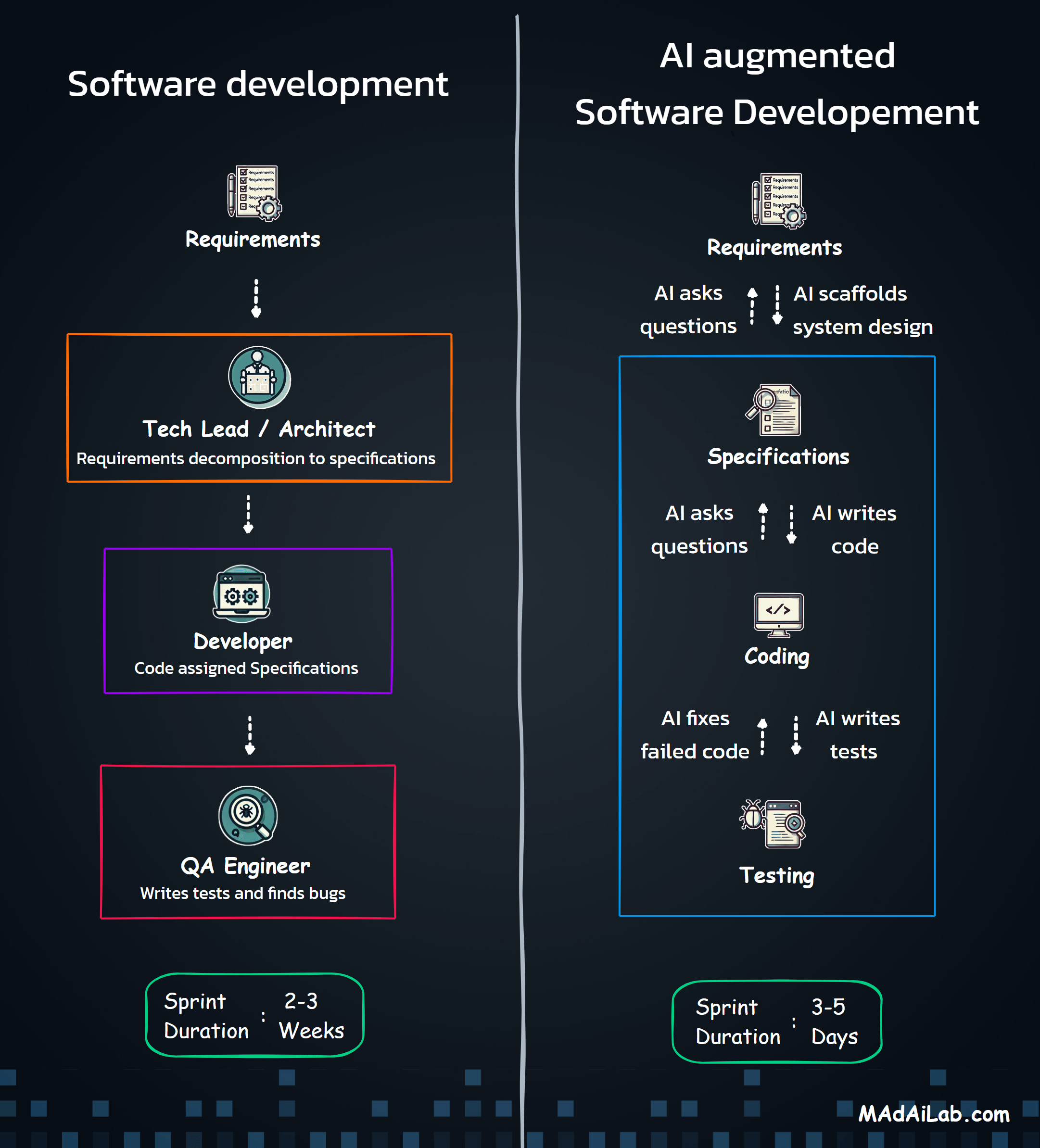
AI can take a large portion of human-dependent work off your plate. No-code tools like n8n let non-technical teams actually put that lift to use. Combine the two, and you get a repeatable way to automate real accounting tasks without spending hours reading SDK documentation.
Here’s the catch: n8n may be no-code, but non-technical users still have to translate a process into nodes, triggers, actions, and properties. With more than 800 connectors and dozens of configuration options per node, that mapping step is where most people get stuck.
In this article, Professor Rohit Aggarwal and I show how a non-technical user can describe requirements in plain English, use AI to scaffold an n8n workflow, and end up with something that actually runs and can be audited. We use a common Finance and Accounting use case as the example - reconciling monthly ISO residuals with daily bank deposits. Whether you’re an AI enthusiast, manager, or student, the goal is simple: learn to automate repetitive work with AI and n8n without needing to master the entire platform first.
What You’ll Learn in Five Minutes
- A requirements template that turns a messy process into clear inputs, outputs, and acceptance checks
- A prompt pattern to ask an AI model for a runnable first draft of an n8n workflow
- A method to generate synthetic CSVs that reproduce real-world reconciliation errors
- A short checklist to make your workflow reliable enough for Finance to trust
Background Context
I like building in loops: observe a messy process, reduce it to patterns, test against noise, and turn the working bits into a machine others can use. That’s how this started. I came across a LinkedIn post where an engineer automated ISO residual reconciliation in n8n. I rebuilt that workflow end to end for my own case.
First, I wrote clear, hand-off-ready requirements - objective, inputs, outputs, and acceptance criteria. I separated platform capabilities from business configuration so nothing was implied. Then, I asked an AI assistant to scaffold n8n nodes from those requirements and generated synthetic ISO and bank files to break my assumptions before production.
Professor Rohit Aggarwal guided the direction, set the clarity standard, and reviewed the drafts. The method below is the outcome.
Step 1: Identify Common Reconciliation Errors with GPT
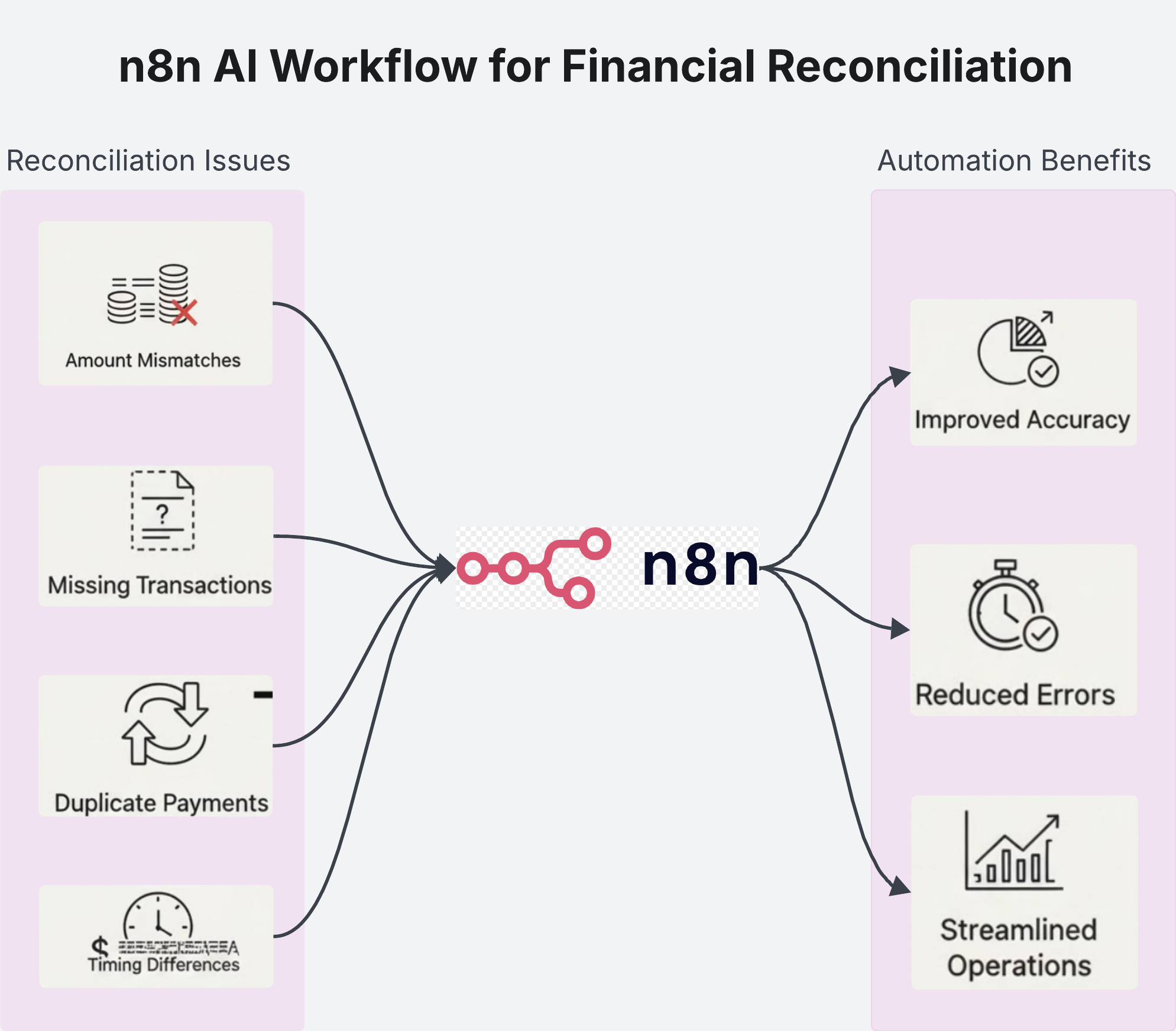
Instead of asking for a bullet list, I treated the model like a research assistant. I described the two source files and asked for concrete rules and edge cases I could code. The most useful categories were:
- Amount mismatches beyond tolerance
- Missing transactions that never appear in the bank feed
- Duplicate payments that inflate received totals
- Timing differences where deposits land a day early or late
- Formatting or currency issues like decimal shifts or encoding surprises
I also asked for quick property tests: if the difference is under X cents, match; if above X, classify as AMOUNT_MISMATCH with severity; if the date gap is within N days, mark as TIME_WINDOW instead of MISSING. Small checks like this keep everything grounded in behavior.
Step 2: Generate Synthetic Data That Bites
Waiting for real data slows teams. I created two CSVs that mimic finance files and deliberately added noise.
- ISO residuals with names, IDs, expected amounts, dates, and types — including decimal shifts, UTF-16 with BOM, and gzipped files to test encoding handling.
- Bank deposits mirroring ISO rows with realistic variation — one- or two-day date offsets, rounding differences, intentional duplicates, and similar amounts under different references to test matching logic.
Each of the five error families had multiple examples, ensuring any rule that only worked on “pretty” data failed fast.
Step 3: Write Requirements Before Touching the Tool
Capabilities:
How files are ingested, any CSV flavor parsed, rows matched, errors classified, results sent to Google Sheets, artifacts archived, and notifications triggered.
Configuration:
Bucket names and folder structures, tolerances for amount/date differences, sheet tabs, distribution lists, retries, and timeouts.
Acceptance Checks:
Run the workflow on one day’s folder, produce a summary of expected vs. received vs. variance, log all five error types, archive inputs and outputs with a manifest, and send an email only when severity crosses a threshold. If any stage fails, stop with a clear, contextual error.
This level of specificity makes AI output safer - you’re grading against a contract, not intuition.
Step 4: Use AI to Scaffold n8n from the Requirements
I pasted the requirements into Claude and asked for a plain-language technical plan that maps directly to n8n: triggers, node list, data flow, error handling, security, retries, and timeouts. Then I requested draft node configurations - manual or webhook trigger, S3 downloads with correct region, CSV extraction with explicit encoding and compression, joins, reconciliations, writes to Sheets, email notifications, and S3 archiving.
The draft wasn’t perfect, but it was a strong starting scaffold. I edited aggressively, removed overly clever expressions, and moved logic into function nodes for testability. The principle: speed with guardrails.
Step 5: Build and Harden the n8n Workflow
The workflow now runs on demand or on a schedule: pull ISO and bank files, normalize CSVs, join on stable keys with fallbacks, classify discrepancies, write summaries to Sheets, notify only when action is required, and archive all inputs and outputs by run.
Common issues and lasting fixes:
- S3 region and path drift: standardize region and date-based paths so downloads never guess.
- Binary and encoding issues: avoid manual parsing; use CSV extraction with explicit encoding and compression.
- Schema mismatches: insert small schema checks between stages to fail fast with clear messages.
- Expression-mode surprises: keep expressions simple and push logic into function nodes.
Once these were implemented, the workflow ran cleanly. The synthetic suite became a reliable safety net - any tweak to tolerances or mappings had to preserve correct classification across the five error families.
Step 6: What You Can Reuse Tomorrow
- A one-page requirements template separating capabilities from configuration
- A prompt that converts those requirements into an initial n8n scaffold
- Synthetic CSVs you can tailor to your own banks and ISOs
- A reliability checklist: region, paths, encoding, schema checks, and minimal expressions
Notes on Scope
This article focuses on generating and hardening an n8n workflow from written requirements using AI. The next article in this series will explore converting an n8n workflow to LangGraph.
Acknowledgments
The direction for this financial reconciliation project originally came from Professor Rohit Aggarwal, who shared the initial article and encouraged me to explore automation for this specific use case. His feedback shaped the framework and kept the project practical.
The first inspiration to try n8n for ISO residual vs. bank deposit matching came from a LinkedIn post by Martha Kruk, who demonstrated a clean, workable approach. Any clarity here comes from that combination of spark and structure - the voice is mine, but the discipline belongs to the mentors who keep me grounded.
About the Author
I’m Yash Kothari, a graduate student at Purdue studying Business Analytics and Information Management. Before Purdue, I spent a few years at Amazon leading ML-driven catalog programs that freed up $20M in working capital, and more recently built GenAI automation pipelines at Prediction Guard using LangChain and RAG. I enjoy taking complex systems whether it’s an AI model or a finance workflow and turning them into simple, repeatable automations that actually work in the real world.
Dr. Rohit Aggarwal is a professor, AI researcher and practitioner. His research focuses on two complementary themes: how AI can augment human decision-making by improving learning, skill development, and productivity, and how humans can augment AI by embedding tacit knowledge and contextual insight to make systems more transparent, explainable, and aligned with human preferences. He has done AI consulting for many startups, SMEs and public listed companies. He has helped many companies integrate AI-based workflow automations across functional units, and developed conversational AI interfaces that enable users to interact with systems through natural dialogue.