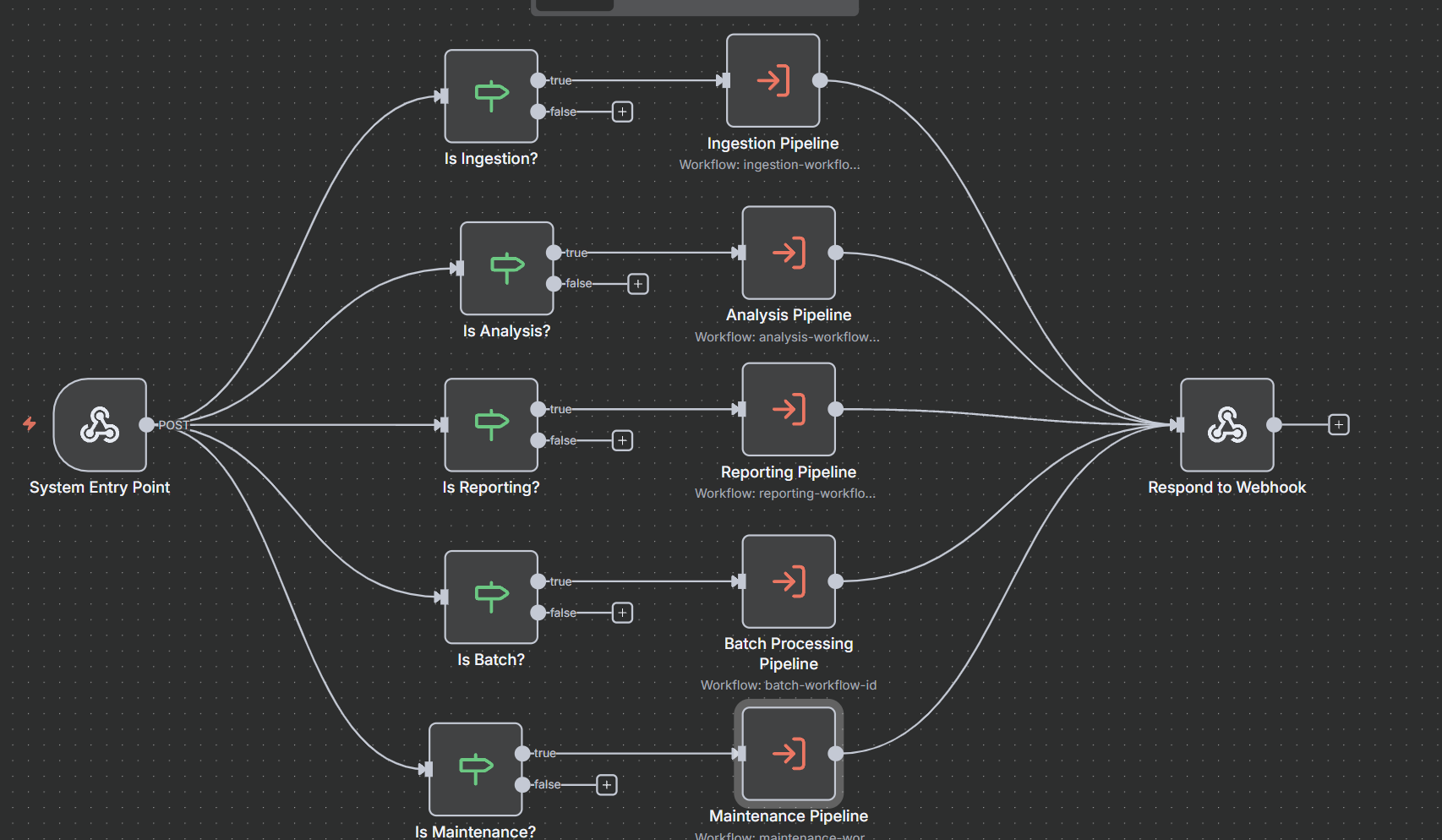
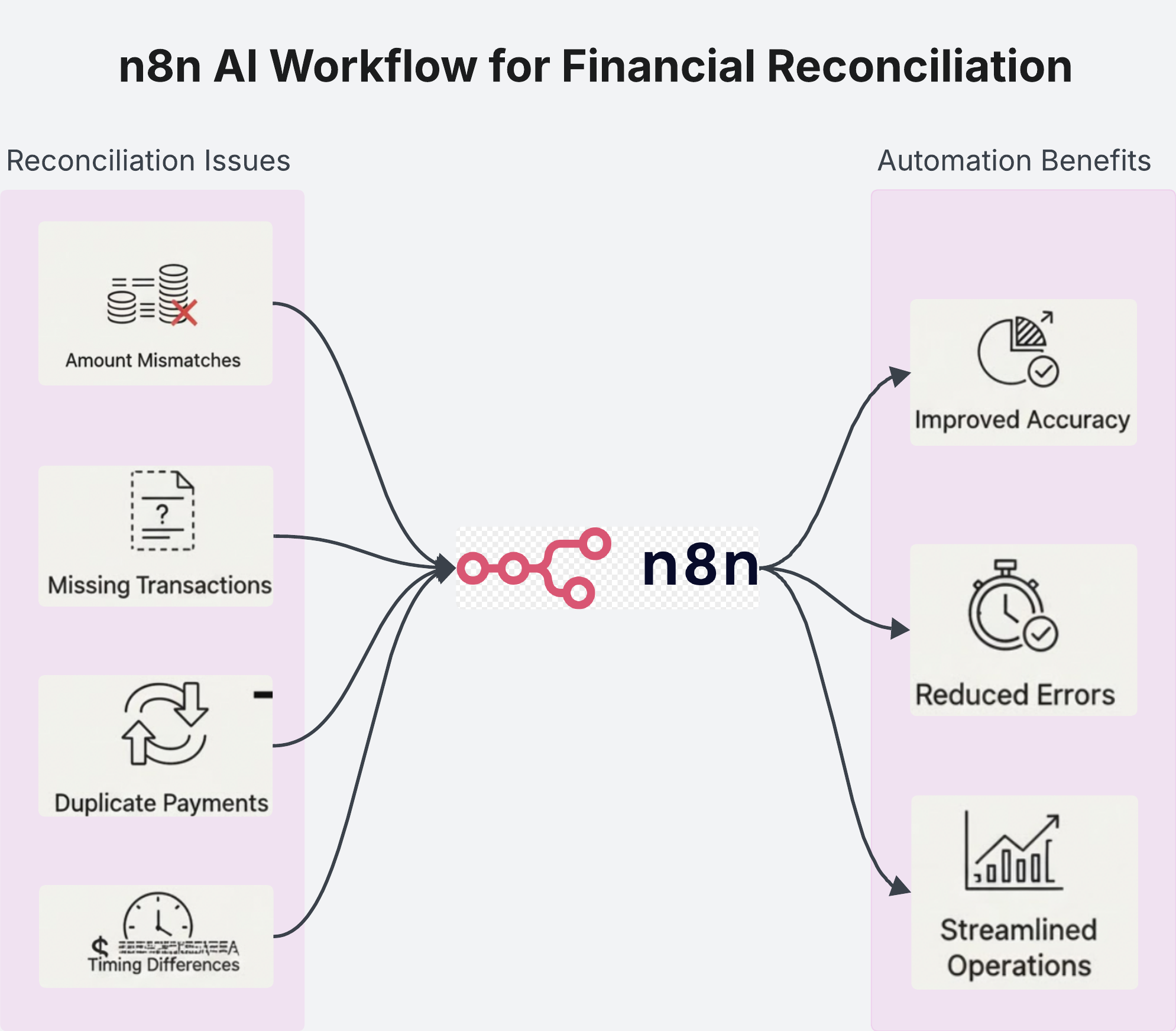
If you are a client, who wants to work remotely from home for US company click here
If you are a startup, then click here to get more information